History of Transcription or Voice-to-Text
Transcription or voice-to-text is the process of converting spoken language into written text. Historically, this task was performed manually by human transcribers, who carefully listened to audio recordings and transcribed the spoken content verbatim.
Voice-to-text services have undergone a remarkable evolution, progressing from rudimentary beginnings to today’s highly advanced platforms. Initially, these systems exhibited limited responsiveness to basic commands, but they have since transformed into sophisticated platforms capable of accurately transcribing complex conversations. This exponential growth can be attributed to significant innovations in machine learning, artificial intelligence, and natural language processing technologies.
The Stages of Transcription
1. Transcription: In the initial phase of transcription, transcribers diligently typed what they discerned from recordings. However, this method was error-prone, susceptible to inaccuracies, and prone to mishearing words. To tackle these challenges, a refined approach emerged, integrating multiple stages of editing and quality assurance. This method aimed to significantly improve the accuracy and reliability of the transcripts.
2. Preliminary Editing: Editors meticulously combed through the transcript, rectifying any discernible errors such as misheard words or punctuation mistakes. Their primary objective was to ensure that the text faithfully mirrored the content of the audio recording.
3. Advanced Editing: Subsequent to the initial review, another round of editing was undertaken to enhance the transcripts further. Editors prioritized enhancing readability, maintaining consistency, and ensuring coherence. Additionally, they addressed any missing words or phrases that were not accurately transcribed during the initial pass.
4. Quality Assurance (QA): QA specialists conducted a meticulous review of the transcripts to guarantee accuracy and completeness. This involved a comprehensive comparison between the transcript and the original audio, verifying each word and sentence to ensure alignment with the required quality standards. Any lingering errors or inconsistencies were promptly rectified during this phase.
5. Publisher Verification: Prior to publication, the transcript undergoes a final check by the publisher or a designated authority. Their role is to ensure that the transcript is free of errors, adheres to the formatting/style guide, and accurately reflects the original content. Upon approval, the transcript is deemed ready for publication.
The Advent of AI
The journey of transcription or voice-to-text towards AI commenced with the inception of speech recognition technology. Early systems, such as IBM’s “Harpy” in the 1970s, paved the way for converting spoken language into text. However, it wasn’t until the emergence of machine learning and deep learning techniques in the late 20th and early 21st centuries that substantial advancements were achieved. With the emergence of neural network models, notably recurrent neural networks (RNNs) and subsequently deep neural networks (DNNs), speech recognition systems experienced a significant boost in accuracy and efficiency. These models became adept at learning intricate patterns within audio data, thereby enabling them to transcribe speech with ever-improving precision.
As artificial intelligence (AI) and natural language processing (NLP) technologies continue to evolve, AI transcription systems have garnered widespread recognition for their efficiency and cost-effectiveness. However, maintaining accuracy in AI transcription is imperative to uphold the reliability and utility of transcribed content. Despite their advancements, AI systems may still encounter challenges such as accurately interpreting nuances in speech or dialects, necessitating ongoing refinement and oversight.
Word Error Rate
With the rise of transcription and voice-to-text services, there emerged a critical necessity for a dependable method to measure the accuracy of transcribed content. This need spurred the development of the Word Error Rate (WER), swiftly establishing itself as the primary metric for evaluating transcription accuracy. As an essential tool in the field, WER offers a standardized approach to assess discrepancies between transcribed text and the original spoken content, enabling transcription providers to gauge their performance accurately and make informed improvements.
The Word Error Rate (WER) stands as the cornerstone for evaluating the accuracy of transcriptions in the industry, maintaining its status as the gold standard over time. It provides a quantitative measure of the ratio of errors within a transcript to the total number of words present. A lower WER indicates higher accuracy in speech recognition. For example, a 10% WER implies that the transcript is 90% accurate, vividly illustrating the efficacy of the transcription process in faithfully capturing the nuances of the spoken content. By leveraging WER as a robust metric, transcription providers can assess performance objectively, driving continuous refinement and enhancement of transcription services.
Quality Parameters
Error Points (EPs): Error Points refer to mistakes or discrepancies in the transcribed text. These errors could include misspellings, omission or addition of words, incorrect proper nouns, or numerical inaccuracies.
Lines: Lines represent the total number of lines in the transcribed text. Each line typically consists of a certain number of words or characters.
Accuracy Percentage (AP): The Accuracy Percentage (AP) is a metric used in transcription to measure the precision of transcribed content. It represents the percentage of correctly transcribed words compared to the total number of words spoken.
The Accuracy Percentage (AP) is calculated by subtracting the Word Error Rate (WER) or Tunk Error Penalty (TEP) from 100.
The Formula for WER
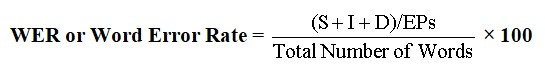
S = Substitutions, some misspellings that are substituted.
I = Insertions, words inserted that were missed or not captured by the transcriber or AI.
D = Deletions, incorrect words captured by the transcriber or AI.
For e.g., let’s use a sample file: EPDL (Heavy Mexican/Latin American Accent) which has a total of 1247 words.
The WER EP or Error Points for EPDL Rev AI is 64.
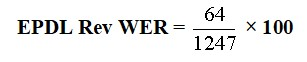
EPDL Rev WER = 5.13%.
So EPDL Rev has a WER of 5.13% or 5.13 per 100 words.
EPDL Rev AP = 100 – 5.13.
So EPDL Rev AP or Accuracy Percentage is 94.87%.
The EPDL WER EP for Tunk is 20.
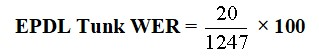
EPDL Tunk WER = 1.6%.
So EPDL Tunk has a WER of 1.6% or 1.6 per 100 words.
EPDL Tunk AP = 100 – 1.6.
So EPDL Tunk AP or Accuracy Percentage is 98.4%.
The limitation of WER stems from its calculation method, which is centered on errors per hundred words. Consequently, a transcript with numerous critical errors could still attain a high score in the 90s. This discrepancy poses a challenge in accurately reflecting the true quality of the transcription, as it may not fully account for the impact of significant errors on overall comprehension and usability.
TEP Method
The TEP (Tunk Error Penalty) method comes into play here. Developed through meticulous analysis of vast amounts of audio data and collaborative brainstorming sessions with leading Quality Assurance (QA) professionals from India, the TEP AP method offers a comprehensive approach to assessing transcription accuracy.
The Formula for TEP
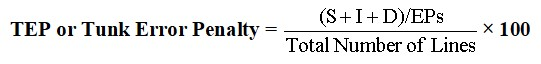
On average, a line typically consists of 10 to 12 words. Therefore, the TEP method for calculating accuracy is notably more stringent and exacting.
Let’s use the above EPDL sample for determining TEP which has a total of 106 lines.
The TEP EP of Rev AI for EPDL is 52.

EPDL Rev TEP = 49.01%.
So EPDL Rev TEP AP = 100 – 49.1.
So EPDL Rev TEP AP is 51%.
The TEP EP of Tunk for EPDL is 16.
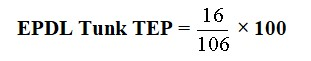
EPDL Tunk TEP = 15.09%.
So EPDL Tunk TEP AP = 100 – 15.09.
So EPDL Tunk TEP AP is 84.91%.
From the above EPDL example, utilizing the WER method, Rev exhibits an AP of 94.87%, while Tunk achieves an AP of 98.4%, resulting in a 3.53% disparity between them. However, upon employing the TEP method, Rev demonstrates an AP of 51%, whereas Tunk attains an AP of 84.91%, indicating a substantial difference of 33.91% between them.
When employing the WER method for EPDL sample, Otter achieves an Accuracy Percentage of 89.26%. When utilizing the TEP method, though, Otter’s Accuracy Percentage plummets to -3.8%, despite securing a WER AP of 90%. So the stringent protocols of the TEP method for calculating Accuracy Percentage (AP) effectively separate the exceptional from the mediocre and the subpar.
In summary of the analysis and comparisons between WER and TEP, it’s evident that while WER has been instrumental in measuring transcription accuracy in voice-to-text conversions, it does have its limitations. The latest advancement in the field is the Tunk Error Penalty (TEP) method, which offers a more precise, dependable, and rigorous approach to assessing transcription accuracy.
With TEP’s emphasis on errors per line rather than errors per hundred words, biases and limitations associated with WER are effectively eliminated. This shift paves the way for the development of even more advanced and accurate voice-to-text technologies. As the undisputed champion of the TEP age, Tunk challenges the voice-to-text giants and establishes a new standard for accuracy and excellence in transcription services.